Simple CSV parser in Mojo
Parsing 400MB per second with less than 80 lines of 🔥
So what is so hard about parsing CSV, isn’t it just .split("\n") and .split(",")? It can be, if you don’t have to comply with the RFC 4180.
RFC 4180 states, that a field can be placed between quotes (") and then it is legal to have new lines and commas as part of the field. So .split("\n") and .split(",") will not work anymore.
Back in 2019 I ported FlexBuffers to C# (FlexBuffers-CSharp) as I wanted to use it for a project I was working on. And since the initial data came as CSV, I also implemented a CSV to FlexBuffers converter.
Nowadays I am exploring a new programming language called Mojo. After taking it for a spin by implementing a function to count chars in UTF-8 string, I decided to go a bit further, brush up my knowledge of CSV parsing and check how good it is going to fly in Mojo.
First, I ported my converter to Mojo with just some small adaptations:
from String import *
from Vector import DynamicVector
struct CsvTable:
var inner_string: String
var starts: DynamicVector[Int]
var ends: DynamicVector[Int]
var column_count: Int
fn __init__(inout self, owned s: String):
self.inner_string = s
self.starts = DynamicVector[Int](10)
self.ends = DynamicVector[Int](10)
self.column_count = -1
self.parse()
@always_inline
fn parse(inout self):
let QUOTE = ord('"')
let COMMA = ord(',')
let LF = ord('\n')
let CR = ord('\r')
let length = len(self.inner_string.buffer)
var offset = 0
var in_double_quotes = False
self.starts.push_back(offset)
while offset < length:
let c = self.inner_string.buffer[offset]
if c == QUOTE:
in_double_quotes = not in_double_quotes
offset += 1
elif not in_double_quotes and c == COMMA:
self.ends.push_back(offset)
offset += 1
self.starts.push_back(offset)
elif not in_double_quotes and c == LF and not in_double_quotes:
self.ends.push_back(offset)
if self.column_count == -1:
self.column_count = len(self.ends)
offset += 1
self.starts.push_back(offset)
elif not in_double_quotes and c == CR and length > offset + 1 and self.inner_string.buffer[offset + 1] == LF:
self.ends.push_back(offset)
if self.column_count == -1:
self.column_count = len(self.ends)
offset += 2
self.starts.push_back(offset)
else:
offset += 1
self.ends.push_back(length)
fn get(self, row: Int, column: Int) -> String:
if column >= self.column_count:
return ""
let index = self.column_count * row + column
if index >= len(self.ends):
return ""
return self.inner_string[self.starts[index]:self.ends[index]]The code is fairly straightforward. I define a structure called CsvTable, which contains a string holding the CSV text. Upon creating an instance of the structure, it determines the starting and ending positions for each field in the table, as well as the number of columns. The calculation occurs byte by byte within the parse function, where it checks for " , \n, or \r characters as specified in RFC 4180 and responds accordingly. The parse function assumes that the CSV is well-formed, meaning that every row has the same number of columns. Additionally, there is a get function that retrieves a field based on the provided row and column indices. If invalid indices are provided, the function returns an empty string, although some may argue that raising an exception would be more suitable.
The CsvTable implementation has certain shortcomings and lacks several evident features, including:
- Type inference for fields
- Removal of quotation marks when returning a field using the
getfunction - Provision of a flag to deviate from RFC-4180 and ignore quotation marks in fields
- Offering the ability to set a different character as the column separator
While it is possible that I may implement these features in the future, my current focus is on SIMD (Single Instruction, Multiple Data) and the resulting performance enhancements.
Back in 2019, a paper called “Parsing Gigabytes of JSON per Second” by Geoff Langdale and Daniel Lemire created quite a buzz. They showed how using SIMD instructions could significantly speed up JSON parsing. The same authors also had a solution for parsing CSV files. I got curious and wanted to try implementing their approach using Mojo. Unfortunately, I ran into some issues because the current Mojo standard library didn’t have all the necessary intrinsics exposed. I could have used MLIR inter-op, but instead, I decided to build the parser using only the standard library’s own structs and functions. Despite the limitations, I managed to create a pretty efficient and, in my opinion, simple and elegant parser.
In the following sections, I will demonstrate my implementation, provide performance benchmarks, and highlight the distinctions between my solution and the one presented by Geoff Langdale and Daniel Lemire.
So, lets start by looking at the SimdCsvTable:
from DType import DType
from Functional import vectorize
from Intrinsics import compressed_store
from Math import iota, any_true, reduce_bit_count
from Memory import *
from Pointer import DTypePointer
from String import String, ord
from TargetInfo import dtype_simd_width
from Vector import DynamicVector
alias simd_width_u8 = dtype_simd_width[DType.ui8]()
struct SimdCsvTable:
var inner_string: String
var starts: DynamicVector[Int]
var ends: DynamicVector[Int]
var column_count: Int
fn __init__(inout self, owned s: String):
self.inner_string = s
self.starts = DynamicVector[Int](10)
self.ends = DynamicVector[Int](10)
self.column_count = -1
self.parse()
@always_inline
fn parse(inout self):
let QUOTE = ord('"')
let COMMA = ord(',')
let LF = ord('\n')
let CR = ord('\r')
let p = DTypePointer[DType.si8](self.inner_string.buffer.data)
let string_byte_length = len(self.inner_string)
var in_quotes = False
self.starts.push_back(0)
@always_inline
@parameter
fn find_indexies[simd_width: Int](offset: Int):
let chars = p.simd_load[simd_width](offset)
let quotes = chars == QUOTE
let commas = chars == COMMA
let lfs = chars == LF
let all_bits = quotes | commas | lfs
let offsets = iota[simd_width, DType.ui8]()
let sp: DTypePointer[DType.ui8] = stack_allocation[simd_width, UI8, simd_width]()
compressed_store(offsets, sp, all_bits)
let all_len = reduce_bit_count(all_bits)
let crs_ui8 = (chars == CR).cast[DType.ui8]()
let lfs_ui8 = lfs.cast[DType.ui8]()
for i in range(all_len):
let index = sp.load(i).to_int()
if quotes[index]:
in_quotes = not in_quotes
continue
if in_quotes:
continue
let current_offset = index + offset
self.ends.push_back(current_offset - (lfs_ui8[index] * crs_ui8[index - 1]).to_int())
self.starts.push_back(current_offset + 1)
if self.column_count == -1 and lfs[index]:
self.column_count = len(self.ends)
vectorize[simd_width_u8, find_indexies](string_byte_length)
self.ends.push_back(string_byte_length)
fn get(self, row: Int, column: Int) -> String:
if column >= self.column_count:
return ""
let index = self.column_count * row + column
if index >= len(self.ends):
return ""
return self.inner_string[self.starts[index]:self.ends[index]]The structure of the struct closely resembles CsvTable, with the main distinction being the implementation of the parse function. To access the underlying string byte buffer with SIMD, we need to represent it as a DTypePointer[DType.si8]. This allows us to use the simd_load method, enabling SIMD operations on vectors of bytes. The find_indices function plays a crucial role in our parsing process. With the help of the vectorize function, we can apply the find_indices function to chunks of the inner_string, effectively converting them into SIMD vectors. Subsequently, we create three bit-sets that indicate whether an element in the vector is equal to ", , or \n, respectively:
let chars = p.simd_load[simd_width](offset)
let quotes = chars == QUOTE
let commas = chars == COMMA
let lfs = chars == LF
let all_bits = quotes | commas | lfsThe all_bits bit-set (a SIMD vector of bools) represents the combination of the markers.
Now we need to transform a SIMD vector of bools into a list of offsets. Which we can do with following four lines:
let offsets = iota[simd_width, DType.ui8]()
let sp: DTypePointer[DType.ui8] = stack_allocation[simd_width, UI8, simd_width]()
compressed_store(offsets, sp, all_bits)
let all_len = reduce_bit_count(all_bits)First we use the iota function to produce a vector of increasing ints starting from zero. Side note: AFAIK the iota function has it’s roots in APL and is also called an index generator.
Moving forward, our objective is to “compress” the offsets using the all_bits vector. This involves removing all instances in the offsets where the corresponding values in all_bits are False. The resulting list’s size will correspond to the number of True values in the all_bits vector. We allocate memory on the stack for the compressed_store function’s result and determine its length by invoking the reduce_bit_count(all_bits) function.
Given the length and the compressed list, we can iterate over the special characters in current text chunk and push start and end offsets if they are not in quotes.
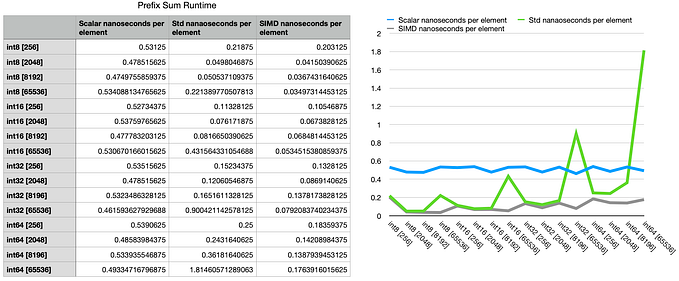
Now it is time to do some benchmarking. I picked the same CSV file which were provided in the simdcsv repo.
For the nfl.csv, I got following result:
SIMD min parse time in nanoseconds:
3135722.0
Non SIMD min parse time in nanoseconds:
4992006.0
Difference
1.5919797737171855
SIMD bytes parsed per nanosecond
0.43519738038002093
Non SIMD bytes parsed per nanosecond
0.27336866181651226And for EDW.TEST_CAL_DT.csv the number are a bit lower:
SIMD min time in nanoseconds:
2007207.0
Non SIMD min time in nanoseconds:
2446398.0
Difference
1.2188070288714616
SIMD byte per nanosecond
0.25521333873387247
Non SIMD byte per nanosecond
0.20939601814586178It’s worth noting that at present, Mojo code can only be run through a cloud-based Jupyter Notebook. This means that the absolute performance numbers may not carry as much weight, but the relative difference between the SIMD and non-SIMD parsers should still hold true. In our analysis, we found that the SIMD parser was around 60% faster for the nfl dataset, while for the second dataset, it showed a modest improvement of about 20%.
To be frank, the performance boost achieved was not as substantial as I had anticipated. However, it still represents a notable improvement, which I consider a win.
Now, let’s discuss why I had to deviate from the solution proposed by Geoff Langdale and Daniel Lemire. In Mojo, when we compare a SIMD vector of integers with an integer, we obtain a SIMD vector of booleans, which is indeed a useful feature. However, I encountered a challenge when trying to perform a shift operation on the boolean vector. In contrast, performing a shift on a bit-set represented as a 64-bit unsigned integer is a straightforward operation. This limitation hindered my ability to replicate certain aspects of the original solution.
Another obstacle I encountered was the need to check if a separator is within quotation marks, which requires the use of carry-less multiplication. Geoff Langdale wrote a blog post explaining the advantages of this approach. Unfortunately, the Mojo standard library does not currently provide access to this rather specialized operation. While it may be possible to expose carry-less multiplication through MLIR inter-op, I opted not to pursue that route for now.
Therefore, due to these limitations in the Mojo standard library, I had to find alternative approaches to address these specific requirements in my implementation, which introduced some branching in the code.
That’s all from my side. Thank you for reading until the end. Feel free to leave a comment. Take care, and until next time!